The Trouble with Tables: A Brief Introduction
![]() May 1, 2017
May 1, 2017

Author: Level Access
First in a three-part series
![]()
This is the first in a three-part series of blog posts that is dedicated to the many people in Government agencies who deal with PDF files on a daily basis, and encounter Section 508 requirements for these files. The Federal Government generates tens of thousands of PDF documents annually, and all of these must be made accessible. This task often falls to Section 508 departments, individual remediators, or even content authors. The goal of this blog series is to highlight special issues (and headaches) that you all will encounter.

The topics I will be addressing will be based on some of the most common errors that we encounter at Level Access when testing PDF files. These posts assume reader familiarity with the Adobe Acrobat tagging system that provides a DOM for screen readers to read in rendering the content will in a particular reading order.
In this post, as well as the next, we will deal with Tables.
This time around, you will not see any pictures of Acrobat tags. That’s because a lot of table problems in Acrobat stem from conceptual problems in how the tables themselves were conceived and executed in Microsoft Word, rather than simple tagging errors.
A table is a totally visual device designed to sort items into categories.
| MAMMALS | BIRDS | MONSTERS |
|---|---|---|
| Bison | Robin | Kraken |
| Sloth | Chicken | Chulhu |
| Weasel | Hummingbird | Godzilla |
The challenge for accessibility is to turn this visual device into a linear series that will be read aloud by a screen reader, such as JAWS or NVDA, so that a non-sighted user can keep track of which item goes into which category. In PDFs, this is done through the tagging system. Whereas visual users can easily use tricks of visual synthesis to elide over errors in table construction, a poorly conceived table will be revealed immediately by a screen reader. If it is bad enough, the screen reader just won’t read a lot of the information; they are merciless with tables.
When we test tables to see how successfully they have been tagged for accessibility, we find these common issues:
Is This a Data Table or a Layout Table?
Layout tables are usually an issue in HTML pages, but we find them in PDF documents as well:

This is actually a layout table, but it is tagged as a data table. This very likely happened because the “table” was arranged this way in Word and when exported to a tagged PDF, the table structure came with it. The problem with this is that the information in the yellow bar at the top is tagged as a header cell, as are each of the number cells on the left side.
This gives the screen reader a completely inaccurate picture of what is being presented here. This is actually a list and would ideally be tagged as a list. We would not necessarily insist that an author tag this as a list to comply with Section 508 — but we would insist that the material in the yellow bar should be tagged as a Caption. The numbers on the left should be tagged as regular data cells. There should be no headers at all tagged in the table.
The simple rule to use when determining if a table is a data table or a layout table:
- If you read the data in a data cell, would you need other information to explain how it relates to other data cells? If so, it’s a data table.
- If the material consists of information that is not categorized, but is sequential or self-explanatory, it should go in a layout table or be tagged as a list.
Is This a Simple Table or a Complex Table?
| Header | Header | Header | Header |
|---|---|---|---|
| Header | Data | Data | Data |
| Header | Data | Data | Data |
| Header | Data | Data | Data |
I have gotten PDFs in which a table like this one has been tagged as a complex table. There are 2 problems with this:
- It isn’t a complex table. That means that the author or developer spent a great deal of time coding it as a complex table when there is no need.
- Complex tables if attempted are rarely done correctly, and should be avoided at all costs. Screen readers vary in their ability to process complex tables well — indeed, there is even variation in their ability to process X — Y tables like this one.
This is a complex table:
| HEADER 1 | *HEADER 2 | *HEADER 3 | HEADER 4 | *HEADER 5 | *HEADER 6 | HEADER7 |
|---|---|---|---|---|---|---|
| *Sub header 1 | *Sub header 2 | *Sub header 3 | *Sub header 4 | |||
| Data | *Data | *Data | Data | *Data | *Data | Data |
| Data | *Data | *Data | Data | *Data | *Data | Data |
| Data | *Data | *Data | Data | *Data | *Data | Data |
| Data | *Data | *Data | Data | *Data | *Data | Data |
We’ll be using this complex table example in another blog post where I will deal with how to tag complex tables in Acrobat XI. The asterisks in the cells above indicate that those cells need special treatment in Acrobat in order for the table to be rendered correctly by the screen reader.
Does This Really Have to Be a Complex Table?
The short answer is: very seldom. However, authors and developers frequently create needleless or unintentional complex tables for a couple of reasons:
- Our authoring tools provide us with a lot of shiny things that are just a lot of fun to use. So we use them, and fill tables with inaccessible color coding and other gimmicks.
- Tables can also be made needlessly complex because they have conceptual problems. Consider the following:
When this document came to us it was tagged as a complex table, because it looks like there are 2 rows of headers, and it was created by the Table Tool in Word. The problem of the two rows can be solved immediately by separating “Sedating Treatment Options for Common Comorbidities” from the table and tagging it as a caption.
The problem, though, is that this table also does not pass the criteria of regularity — meaning that there are the same number of rows and columns throughout. The “Insomnia” cell spans 6 rows and has the appropriate row span attributes in Acrobat, but it will be read inconsistently by screen readers. Imagine listening to this table rendered by a screen reader—it’s likely that it would be hard to make sense of it.
The underlying problem with this table is conceptual: if you have a header cell that must span 6 rows, along with 10 empty cells of data, there is a good chance that the table itself is not well thought out.
The table purports to be about common comorbidities, but all of the comorbidities have one thing in common: insomnia. Given that, the caption could read: “Sedating Treatment Options for Insomnia and:”
Once that has happened, is there any reason why each drug name must have its own cell? The table is a lot simpler and easier to understand like this:
Sedating Treatment Options for Insomnia and:
| Pain | Depression | Anxiety Disorders | PTSD | Substance Use |
|---|---|---|---|---|
| Gabapentin
Amitriptyline Doxepin |
Mirtazapine
Doxepin Trazodone Amitriptyline |
Mirtazapine
Doxepin Trazodone Amitriptyline Hydroxyzine Temazepam |
Prazosin (for trauma associated nightmares)
Mirtazapine Doxepin Trazodone Amitriptyline Hydroxyzine |
Gabapentin |
The most frequently occurring type of needlessly complex table is the following:
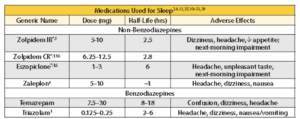
As originally tagged, there were 3 consecutive rows of headers, 2 of which had a column span of 4. This would be a nightmare to tag correctly as a complex table. As in the other tables, the text in the yellow bar can be tagged as a caption. “Non-benzodiazepines” and “Benzodiazepines” do not belong in the table at all. This should be split into 2 simple tables, one for non-benzodiazepines and the other for benzodiazepines. The headers should be repeated in both tables.
Authors and developers, by importing inappropriate headers (which should be external headings) into tables create enormous problems for Section 508 personnel downstream who must make these documents accessible. Optimally, such tables could be sent back to the authors to be restructured in Microsoft Word and then exported to tagged PDF again. If that is not possible, or if the document is already in the Federal Register, the Section 508 personnel have to do what they can to make the existing document as accessible as possible. Those solutions can get radical and very involved, and take up a great deal of time. A good remediator can tag three or four complex tables in one work day. And doing that can be fraught with difficulties, as I will demonstrate in the next post on tagging complex tables.
Share

Subscribe for updates
